写在前面
使用tensorflow接近一年时间,然而一直使用的是cpu版本的,而且还是在笔记本上跑程序的,所以当训练模型时,你懂的,我都心疼我的笔记本,最近公司刚刚给配了台带了块GTX 1080的台式机。嗯,终于算入门了,台式机的配置如下:
System:Ubuntu 16.04 LTS CPU: Intel(R) Core(TM) i7-7700 CPU @ 3.60GHz MemTotal: 16295024 kB GPU: GeForce GTX 1080
目前来说够用了。大佬就可以忽略这段的。下面说说我在安装配置tensorflow-gpu的时候遇到的问题
一、N卡驱动安装
1、ubuntu自带
安装之前使用sudo apt-get install upgrade将系统的软件进行升级。
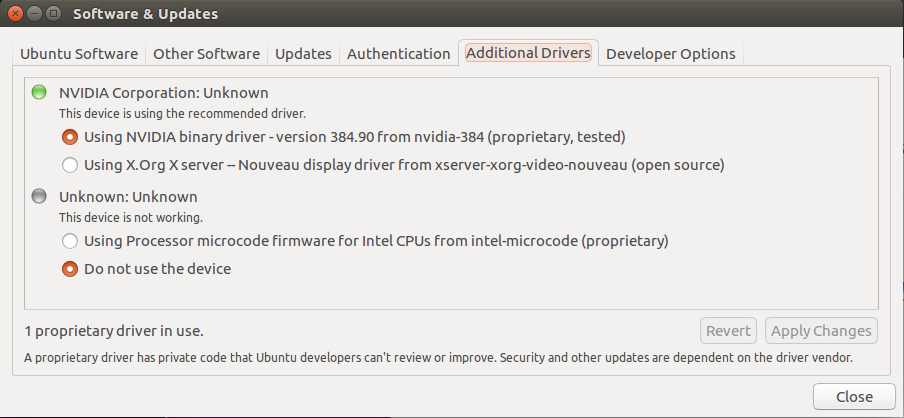
然后在System Settings -> Software&Update -> Additional Drivers 下,等待刷新完毕后,会出现 NVIDIA Corporation:Unknown,如下图所示。然后勾选第一个选项,然后点击更新。更新完成后重启电脑。
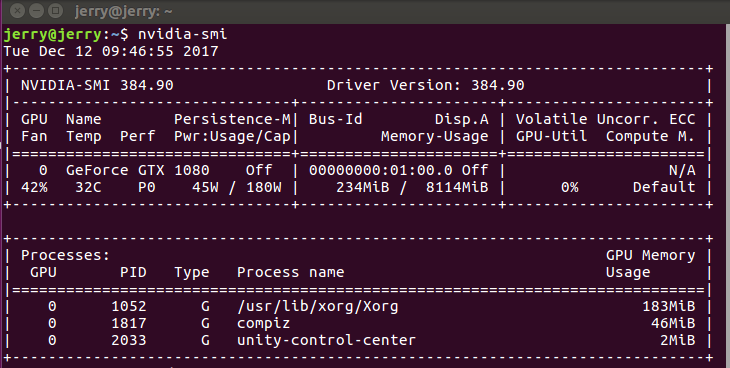
重新打开终端,输入nvidia-smi,就会出现显卡的相关信息, 如下图所示。
#### 主意;用这种方法在安装cuda9.1的时候会出现状况。在运行测试用例的时候,系统会提示cuda驱动版本不一致,我查看了下官方此时已经更新到390.48了。
2、Nvidia官网下载对应显卡驱动安装
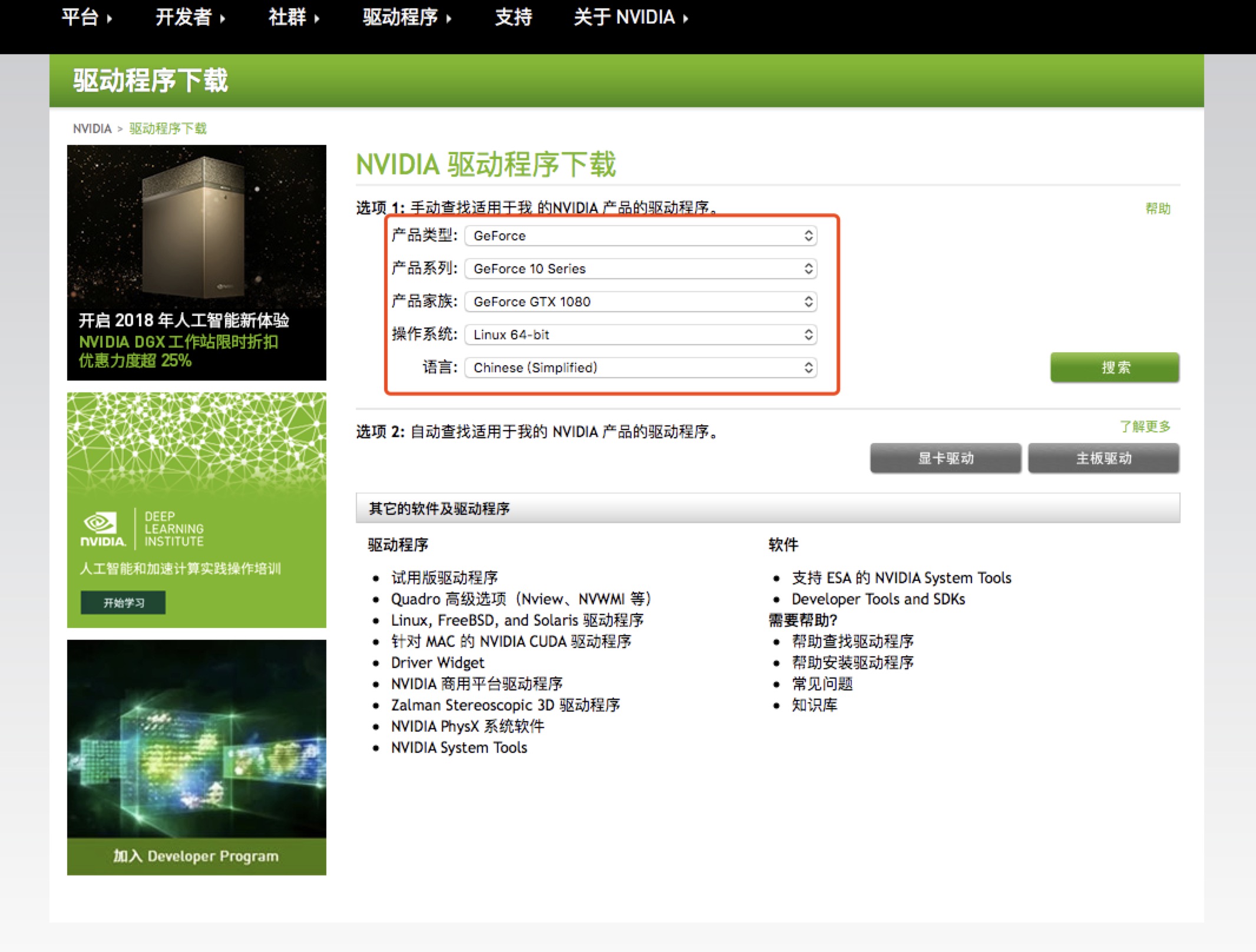
1、去nvidia官网下载对应的驱动,根据自己的显卡型号和操作系统手动查找对应的驱动文件,我的显卡是GTX1080,所以下载的驱动文件名为NVIDIA-Linux-x86_64-390.48.run。如下图所示。
2、先卸载原有N卡驱动
#for case1: original driver installed by apt-get: sudo apt-get remove --purge nvidia* #for case2: original driver installed by runfile: sudo chmod +x *.run sudo ./NVIDIA-Linux-x86_64-384.59.run --uninstall
如果原驱动是用apt-get安装的,就用第1种方法卸载。
如果原驱动是用runfile安装的,就用–uninstall命令卸载。其实,用runfile安装的时候也会卸载掉之前的驱动,所以不手动卸载亦可。
3、禁用nouveau驱动
创建或更新blacklist-nouveau.conf,有的教程中会更新blacklist.conf
sudo vi /etc/modprobe.d/blacklist-nouveau.conf or sudo vi /etc/modprobe.d/blacklist.conf
在文本最后添加:(禁用nouveau第三方驱动,之后也不需要改回来)
blacklist nouveau options nouveau modeset=0
然后执行:sudo update-initramfs -u, 重新生成 kernel initramfs
重启后,执行:lsmod | grep nouveau。如果没有屏幕输出,说明禁用nouveau成功。
4、禁用X-Window服务
sudo service lightdm stop #这会关闭图形界面,但不用紧张
按Ctrl-Alt+F1进入命令行界面,输入用户名和密码登录即可。
小提示:在命令行输入:sudo service lightdm start ,然后按Ctrl-Alt+F7即可恢复到图形界面。
5、命令行安装驱动
#给驱动run文件赋予执行权限: sudo chmod +x NVIDIA-Linux-x86_64-384.59.run #后面的参数非常重要,不可省略: sudo ./NVIDIA-Linux-x86_64-384.59.run –no-opengl-files
- –no-x-check:表示安装驱动时不检查X服务,非必需。
- –no-nouveau-check:表示安装驱动时不检查nouveau,非必需。
- -Z, --disable-nouveau:禁用nouveau。此参数非必需,因为之前已经手动禁用了nouveau。
- -A:查看更多高级选项。
必选参数解释:因为NVIDIA的驱动默认会安装OpenGL,而Ubuntu的内核本身也有OpenGL、且与GUI显示息息相关,一旦NVIDIA的驱动覆写了OpenGL,在GUI需要动态链接OpenGL库的时候就引起问题。之后,按照提示安装,成功后重启即可。
如果提示安装失败,不要急着重启电脑,重复以上步骤,多安装几次即可。
Driver测试:
nvidia-smi #若列出GPU的信息列表,表示驱动安装成功 nvidia-settings #若弹出设置对话框,亦表示驱动安装成功
二、安装cuda
1、检查自带的nouveau nvidia驱动是否禁用。
如果安装cuda和安装显卡驱动没有同时进行,则需要检查这一步,同样安装cuda和显卡驱动都需要禁用nouveau驱动。
2、Ctrl + Alt + F1 进入命令行模式,执行,
$ sudo service lightdm stop // 关闭桌面服务
在安装CUDA的过程中必须得关闭桌面服务。
当然,你也可以在终端中执行关闭桌面服务操作,然后使用 Ctrl + Alt + F1 登陆你的账号。我在安装的过程中是先关闭桌面服务然后使用Ctrl + Alt + F1进入终端然后重新登陆账号密码的。
注,在安装nvidia显卡驱动和cuda的时候都需要关闭桌面服务,或者可以在安装完显卡驱动之后不恢复图形界面,直接安装cuda。
3、安装CUDA.run文件
我用的是是CUDA8.0的版本,刚开始安装的是最新9.0的版本,后来好像在某篇教程中看到tensorflow目前还不支持CUDA9.0版本的,所以重装了8.0的,也有可能我没有理解他的意思,我没有经过实测。还有就是很多教程直接使用.deb安装的CUDA,同事反应在升级的过程中直接安装没有问题,但是后面使用的时候就会出现一些问题,所以我也没有直接安装,后面遇到的问题也没办法复现。
sudo sh cuda_8.0.61_375.26_linux.run --no-opengl-libs
在.run文件后面添加--no-opengl-libs的详解见Ubuntu 14.04 安装 CUDA 问题及解决,安装完成后需要将opengl的相关lib重新安装一下。
运行之后会跳出readme文件,然后按住Ctrl + C跳过。然后会依次出现以下提示:
Do you accept the previously read EULA, 输入 accept,进入下一步。 INSTALL NVIDIA Accelerates Graphics Driver for Linux-x86_64 375.26, 输入n,进入下一步; Install the CUDA 8.0 Toolkit?, 输入y, 进入下一步; Enter Tookit Location 点击enter, 进入下一步; Do you want to install a symbolic link at /usr/local/cuda, 输入y,进入下一步; Install the CUDA 8.0 Samples? 输入y, 进入下一步; Enter CUDA Samples Location 点击enter, 进入下一步; 程序开始安装。。。
更详细的提示见Ubuntu16.04 下安装GPU版TensorFlow(包括Cuda和Cudnn)
安装完成之后,会提示一个summary;大致内容如下。
Driver: Not Selectd Toolkit: INstalled in /usr/local/cuda-8.0 Samples: Installed in /home/jerry, but missing recommended libraries
注意
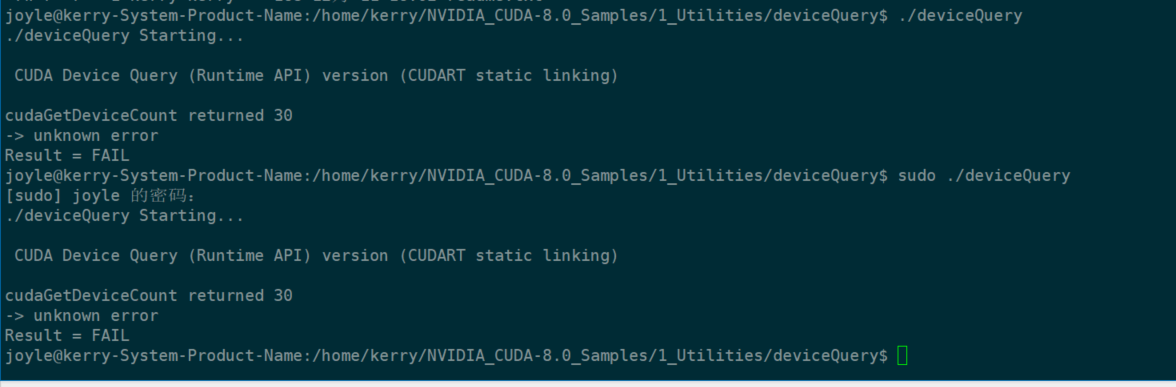
这时候会有一个提示,类似于下图,fail的原因是CUDA Driver没有安装。也有人说是因为双显卡(独立显卡和集成显卡)的原因。
程序下面又一个warning:
***WARNING: Incomplete installation! This installation did not install the CUDA Driver. A driver of version at least 361.00 is required for CUDA 8.0 functionality to work. To install the driver using this installer, run the following command, replacing <CudaInstaller> with the name of this run file: sudo <CudaInstaller>.run -silent -driver
根据warning提示,在.run文件后面添加-silent -driver,有提示的图片忘记保存了。以后遇到在加上。
sudo sh cuda_8.0.61_375.26_linux.run -silent -driver
安装完成之后,启动桌面
$ sudo service lightdm start // 重启桌面服务
为了检查安装是否正确,从cuda的samples中选择样例进行测试。
cd /usr/local/cuda-7.5/samples/1_Utilities/deviceQuery sudo make clean && make sudo ./deviceQuery
注意,我在升级tensorflow至1.7后,此时cuda需要升级到cuda9.0,在安装cuda9.0的过程中,Driver显示的是Not Selectd,但是使用sudo <CudaInstaller>.run -silent -driver的方式并没有能够安装成功。但是我在使用samples中的样例测试也是可以的,没有出问题。所以这边Driver有没有select好像没有什么区别。对后面安装cudnn和tensorflow-gpu都没有什么影响。后面没有出现问题,所以也就没有去解决。(更新时间4月18日)
如果显示的是一些关于GPU的信息,则说明安装成功了,详细信息见下图。
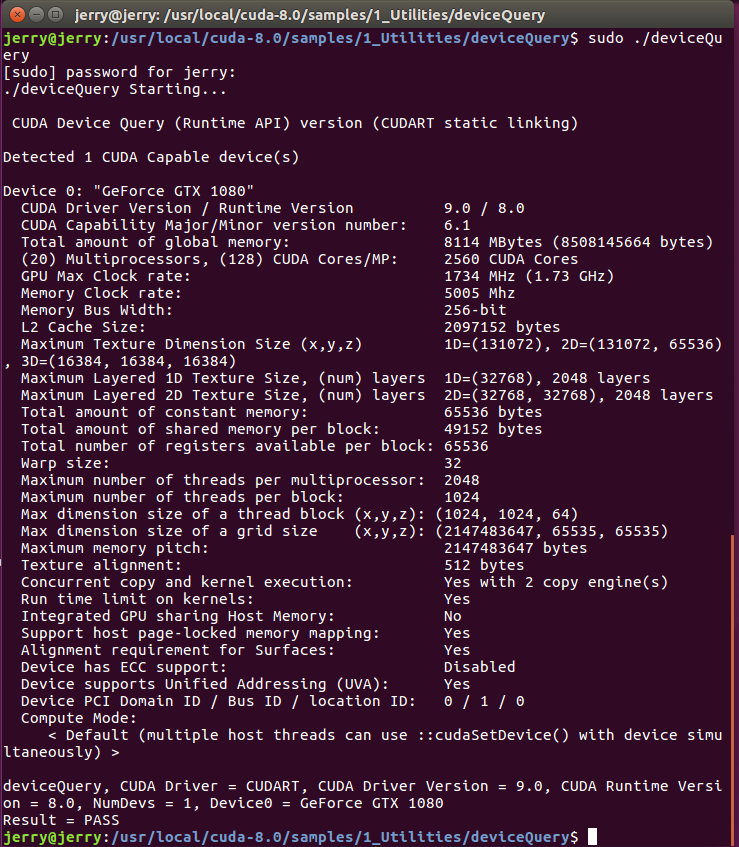
配置环境变量
在CUDA安装完成之后,log日志中有提示需要声明环境变量,不然后面安装cudnn时会出现找不到.so文件。所以需要在/etc/profile中添加下面的内容。
PATH=/usr/local/cuda/bin:$PATH export PATH LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64 export LD_LIBRARY_PATH
最后source /etc/profile即可。
三、安装cudnn
在CUDA安装好之后,CUDNN安装相对比较容易,根据官网教程,首先从官网上下载四个文件。
cudnn-8.0-linux-x64-v7.tgz libcudnn7_7.0.5.15-1+cuda8.0_amd64.deb libcudnn7-dev_7.0.5.15-1+cuda8.0_amd64.deb libcudnn7-doc_7.0.5.15-1+cuda8.0_amd64.deb
注意
在安装cudnn的时候要特别注意tensorflow目前支持的cudnn版本,我这边直接下载的是最新的,后面在安装完tensorflow-gpu 1.4.1之后调用cudnn时就出现了错误,错误提示为ImportError: libcudnn.so.6: cannot open shared object file: No such file or directory。
我的解决方法是从官网上直接下载cudnn.6.0版本的,至于软链接等方式我试过了没有成功,后面有详细介绍,也可能是我添加环境变量错误导致。
根据对应的系统和cuda版本下载,我的系统是ubuntu16.04,cuda版本为8.0.最好再注意下tensorflow支持的cudnn版本,然后需要注意的是cuda的安装路径,如果在安装cuda使用的默认路径/usr/local/cuda/,则不需要修改。
在存放四个文件的下载目录下。
# 解压 cuDNN package. $ tar -xzvf cudnn-8.0-linux-x64-v7.tgz # 将下面的文件复制到 CUDA Toolkit 文件目录下。 $ sudo cp cuda/include/cudnn.h /usr/local/cuda/include $ sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64 $ sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn* # 安装 runtime library, sudo dpkg -i libcudnn7_7.0.5.15-1+cuda8.0_amd64.deb # 安装 developer library, sudo dpkg -i libcudnn7-dev_7.0.5.15-1+cuda8.0_amd64.deb # 安装 code samples and the cuDNN Library User Guide sudo dpkg -i libcudnn7-doc_7.0.5.15-1+cuda8.0_amd64.deb
验证cudnn是否安装正确
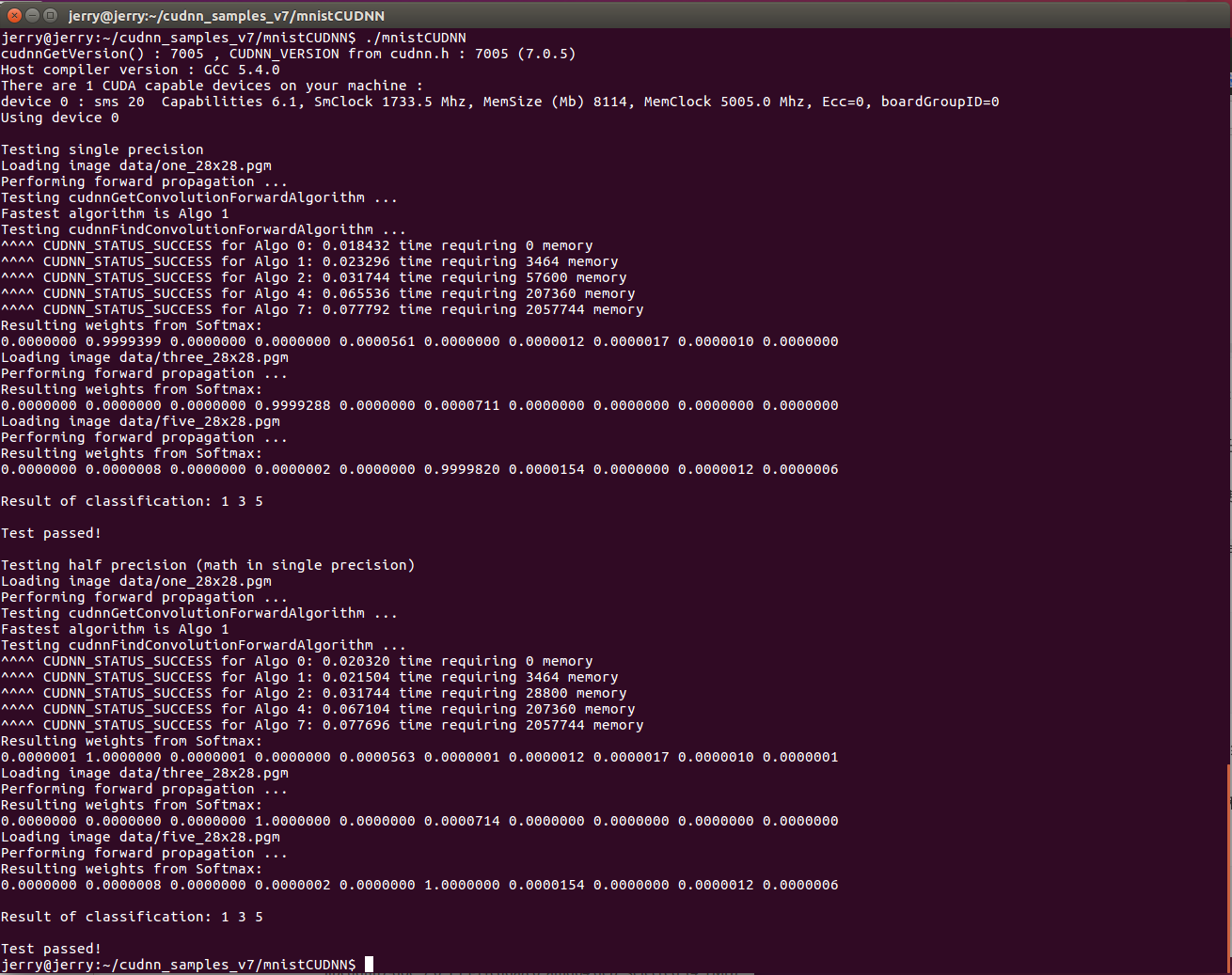
1. 将某一个 cuDNN 样例复制到某一可读写文件目录下 $ cp -r /usr/src/cudnn_samples_v7/ $HOME 2. 进入该文件目录, 本文选择的是mnistCUDNN测试 $ cd $HOME/cudnn_samples_v7/mnistCUDNN 3. 编译 mnistCUDNN 样例. $ make clean && make 4. 运行 mnistCUDNN 样例. $ ./mnistCUDNN 5. 如果安装成功,程序的最后则会显示 Test passed!
详细运行结果如下图所示:
四、安装gpu版tensorflow
本文使用的是virtualenv安装的tensorflow。
现在tensorflow越来越成熟了,所以在虚拟环境下直接可以用pip install --upgrade tensorflow-gpu即可安装成功。
安装完成后,进入python环境测试一下,问题来了。
错误提示
Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/home/jerry/workshop/virtualenv/tensor/local/lib/python2.7/site-packages/tensorflow/__init__.py", line 24, in <module> from tensorflow.python import * File "/home/jerry/workshop/virtualenv/tensor/local/lib/python2.7/site-packages/tensorflow/python/__init__.py", line 49, in <module> from tensorflow.python import pywrap_tensorflow File "/home/jerry/workshop/virtualenv/tensor/local/lib/python2.7/site-packages/tensorflow/python/pywrap_tensorflow.py", line 59, in <module> raise ImportError(msg) ImportError: Traceback (most recent call last): File "/home/jerry/workshop/virtualenv/tensor/local/lib/python2.7/site-packages/tensorflow/python/pywrap_tensorflow.py", line 48, in <module> from tensorflow.python.pywrap_tensorflow_internal import * File "/home/jerry/workshop/virtualenv/tensor/local/lib/python2.7/site-packages/tensorflow/python/pywrap_tensorflow_internal.py", line 28, in <module> _pywrap_tensorflow_internal = swig_import_helper() File "/home/jerry/workshop/virtualenv/tensor/local/lib/python2.7/site-packages/tensorflow/python/pywrap_tensorflow_internal.py", line 24, in swig_import_helper _mod = imp.load_module('_pywrap_tensorflow_internal', fp, pathname, description) ImportError: libcudnn.so.6: cannot open shared object file: No such file or directory Failed to load the native TensorFlow runtime. See https://www.tensorflow.org/install/install_sources#common_installation_problems for some common reasons and solutions. Include the entire stack trace above this error message when asking for help.
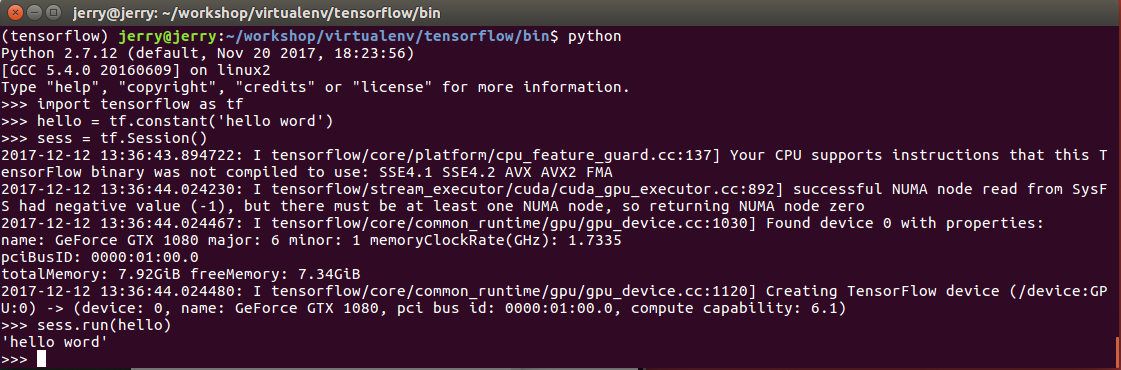
在网上查资料发现,需要进行软链接配置,主要原因依然是环境变量的问题,但是按照一些方式还是提示上面的错误,后来查看lib64下面的文件发现我安装的是.so.8.0的版本,本来是想都安装最新版本的,慢慢发现google和nvidia两家根本不同步,版本的一致性问题很头疼。没办法,在nvidia官网重新下载6.0版本的cudnn按照上面的方式重新安装后,在没有重新设置环境变量的情况下,helloword程序跑通了
下面是执行session时输出的信息,GPU信息显示出来了。
2017-12-12 13:36:43.894722: I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA 2017-12-12 13:36:44.024230: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:892] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2017-12-12 13:36:44.024467: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1030] Found device 0 with properties: name: GeForce GTX 1080 major: 6 minor: 1 memoryClockRate(GHz): 1.7335 pciBusID: 0000:01:00.0 totalMemory: 7.92GiB freeMemory: 7.34GiB 2017-12-12 13:36:44.024480: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1120] Creating TensorFlow device (/device:GPU:0) -> (device: 0, name: GeForce GTX 1080, pci bus id: 0000:01:00.0, compute capability: 6.1)
具体运行结果如下图所示:
至此,基于Ubuntu的tensorflow-gpu版本就安装配置完成,下面就可以畅快的"吃鸡"啦。
五、一些问题
1、驱动问题
我在安装过程中涉及到两个驱动问题,一个是显卡驱动,还有一个是CUDA驱动。显卡驱动我直接先是使用sudo apt-get install upgrade升级安装包,然后在Ubuntu的设置里面更新的Nvidia显卡驱动。并没有从官网下载安装对应版本的显卡驱动。CUDA驱动,我最初在安装CUDA的时候选项全部选择的是yes,导致最后的Driver、Toolkit和Samples都没有安装成功,后来所有教程中都加第二步是否安装图形显卡驱动时选择No,按照教程设置后Toolkit和Samples都安装成功了,但是Driver先是没有选择,安装结束后有一个warning,CUDA的驱动没有安装,根据提示在CUDA.run文件后面添加-silent -driver之后,对应的log文件中会先是Driver: Installed.
2、关于cuda环境变量和更新软链接问题
最终在我的/etc/profile下面添加的内容如下:
PATH=/usr/local/cuda/bin:$PATH export PATH export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda-8.0/lib64:/usr/local/cuda-8.0/extras/CUPTI/lib64" export CUDA_HOME=/usr/local/cuda-8.0
我也没用到软链接之类的。
3、failed call to cuInit: CUDA_ERROR_UNKNOWN
在系统能够正常运行的情况下,轻易不要去更新显卡驱动,Nvidia动不动就会出新的驱动更新,我建议是不是大版本更新,能不更新尽量不更新,我就遇到了问题,每次登录系统的时候系统都会提示例如几个packages can be update,我觉得碍眼就直接使用sudo apt-get upgrade升级安装包,突然发现她在帮我更新显卡驱动,虎躯一震,感觉要出问题。等更新完成之后我立刻运行我的tensorflow程序,问题真的来了。
问题提示""failed call to cuInit: CUDA_ERROR_UNKNOWN""
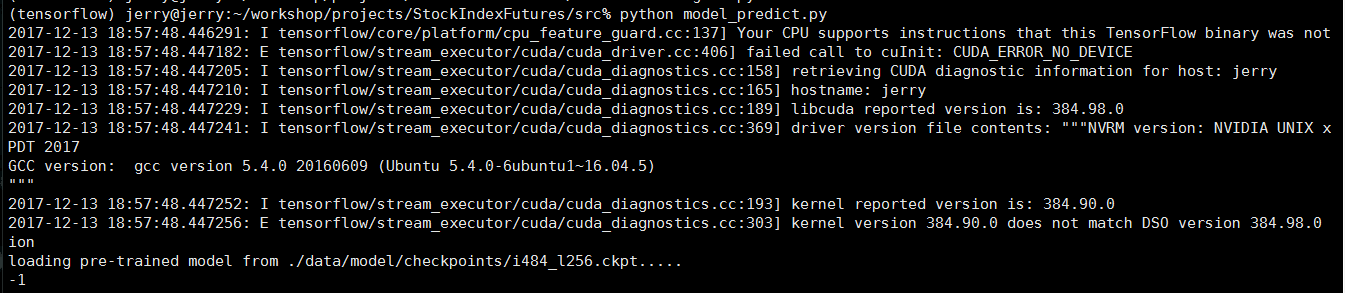
网上的解决方法:
第一种解决方法是
sudo apt-get install nvidia-modprobe,我尝试了,好像没有用。还是会报同样的错误。第二种解决方法是 直接使用
sudo来运行程序。具体可以参考failed call to cuInit: CUDA_ERROR_UNKNOWN in python programs using Ubuntu bumblebee。
内核版本不匹配,那我就按照上面的方式重装cuda。
重装之后运行程序,问题解决

4、添加lib库路径
后续
tensorflow升级至1.7版本后,如果继续使用cuda 8.0则会报下面的错误:
--------------------------------------------------------------------------- ImportError Traceback (most recent call last) <ipython-input-1-64156d691fe5> in <module>() ----> 1 import tensorflow as tf /home/jerry/workshop/virtualenv/tensor_jupyer/local/lib/python2.7/site-packages/tensorflow/__init__.py in <module>() 22 23 # pylint: disable=wildcard-import ---> 24 from tensorflow.python import * # pylint: disable=redefined-builtin 25 # pylint: enable=wildcard-import 26 /home/jerry/workshop/virtualenv/tensor_jupyer/local/lib/python2.7/site-packages/tensorflow/python/__init__.py in <module>() 47 import numpy as np 48 ---> 49 from tensorflow.python import pywrap_tensorflow 50 51 # Protocol buffers /home/jerry/workshop/virtualenv/tensor_jupyer/local/lib/python2.7/site-packages/tensorflow/python/pywrap_tensorflow.py in <module>() 72 for some common reasons and solutions. Include the entire stack trace 73 above this error message when asking for help.""" % traceback.format_exc() ---> 74 raise ImportError(msg) 75 76 # pylint: enable=wildcard-import,g-import-not-at-top,unused-import,line-too-long ImportError: Traceback (most recent call last): File "/home/jerry/workshop/virtualenv/tensor_jupyer/local/lib/python2.7/site-packages/tensorflow/python/pywrap_tensorflow.py", line 58, in <module> from tensorflow.python.pywrap_tensorflow_internal import * File "/home/jerry/workshop/virtualenv/tensor_jupyer/local/lib/python2.7/site-packages/tensorflow/python/pywrap_tensorflow_internal.py", line 28, in <module> _pywrap_tensorflow_internal = swig_import_helper() File "/home/jerry/workshop/virtualenv/tensor_jupyer/local/lib/python2.7/site-packages/tensorflow/python/pywrap_tensorflow_internal.py", line 24, in swig_import_helper _mod = imp.load_module('_pywrap_tensorflow_internal', fp, pathname, description) ImportError: libcublas.so.9.0: cannot open shared object file: No such file or directory Failed to load the native TensorFlow runtime. See https://www.tensorflow.org/install/install_sources#common_installation_problems for some common reasons and solutions. Include the entire stack trace above this error message when asking for help.
也就是说 tensorflow兼容的cuda也已经升级至9.0了,下面介绍下在ubuntu 16.04下升级安装cuda 9.0,这里本来想在cuda8.0的基础上直接覆盖安装cuda9.0的,结果没有成功,编译cuda实例源码的时候使用提示没有找到driver。在这之前一直是使用ubuntu系统本身的升级系统来更新nvidia驱动的,并没有使用源码安装显卡驱动。后来不停的重装cuda的过程中反而把系统给弄坏了,最后实在没办法重装系统。
在这里我又跳到坑里了,tensorflow 1.7目前暂时不支持cudnn9.1,所以我又得重新安装cudnn了(4月17号更新)
注意,在安装cuda和dudnn的时候版本一定要一致。重装系统后,我装了cuda_9.0.176_384.81_linux和cudnn-9.0-linux-x64-v7.1,tensorflow的版本为1.7.0,安装过程中没有出现什么太大的问题,基本跟cuda8.0安装过程差不多。
六、参考文献
Ubuntu 14.04 安装 CUDA 问题及解决
Ubuntu16.04+cuda8.0+caffe安装教程
CUDNN Installation Guide
Ubuntu16.04 下安装GPU版TensorFlow(包括Cuda和Cudnn)
"libcudnn.so.5 cannot open shared object file: No such file or directory"
ldconfig提示is not a symbolic link警告的去除方法
Ubuntu16.04.1如何安装TensorFlow1.1.0(GPU版)
failed call to cuInit: CUDA_ERROR_UNKNOWN in python programs using Ubuntu bumblebee