写在前面
使用LSTM进行MNIST手写字符分类的Tensorflow代码其官方教程中就已经给出,很多其他的教程中也就把他拿过来作为lstm在分类中的应用作为讲解,但是很多代码依然是基于tensorflow官网代码。
本教程中主要的代码跟官网没有差别,比如rnn_cell的定义,超参的设置也基本相同,本文主要的侧重点在给出了training_model和testing_model,并且结合tensorboard将训练和测试过程中的accuracy和loss展现出来。
这里面涉及的主要问题是训练模型和测试模型的参数共享,以及tf.summary的应用。
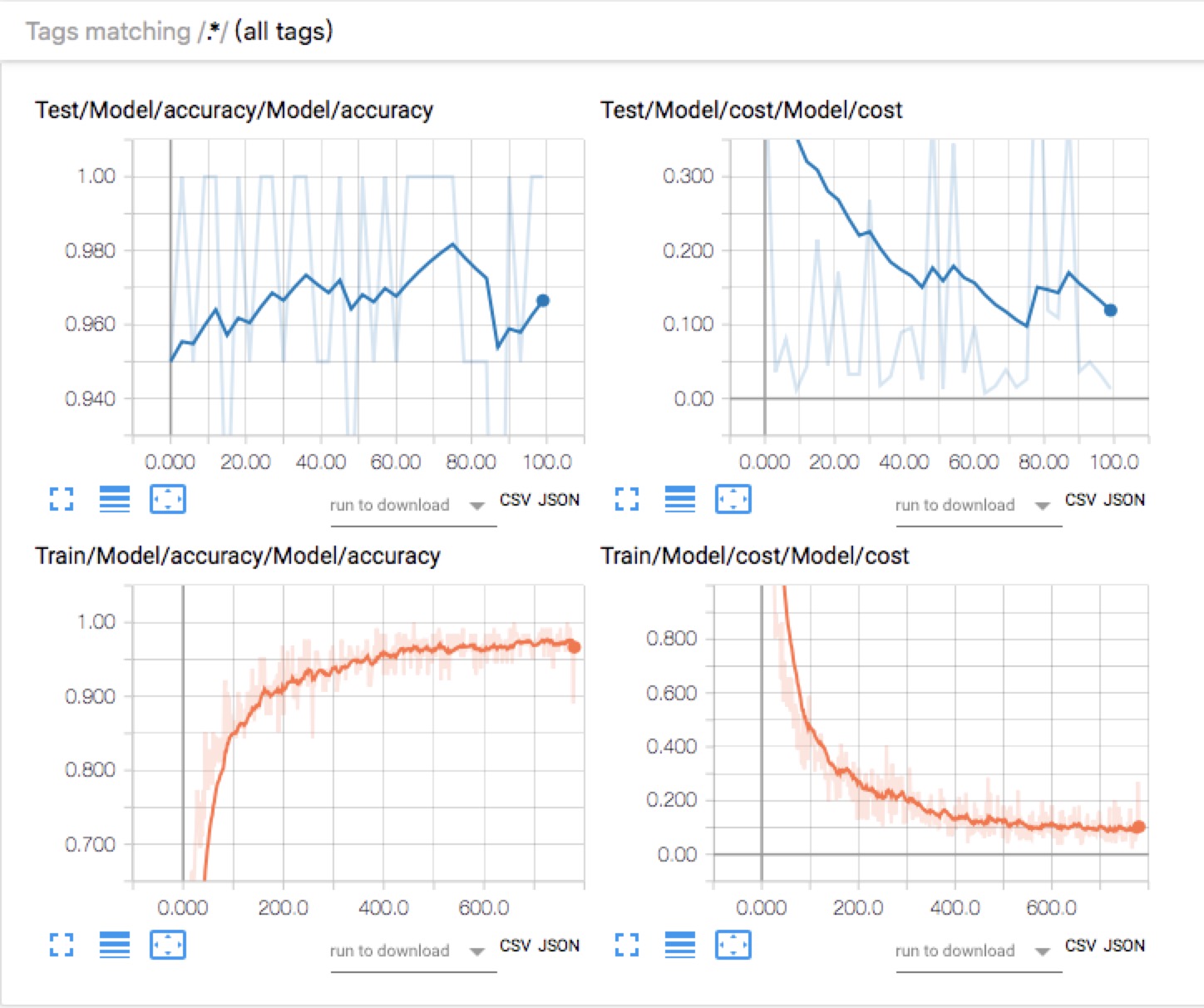
我们先看下正确的结果:
模型训练和测试的accuracy 和cost
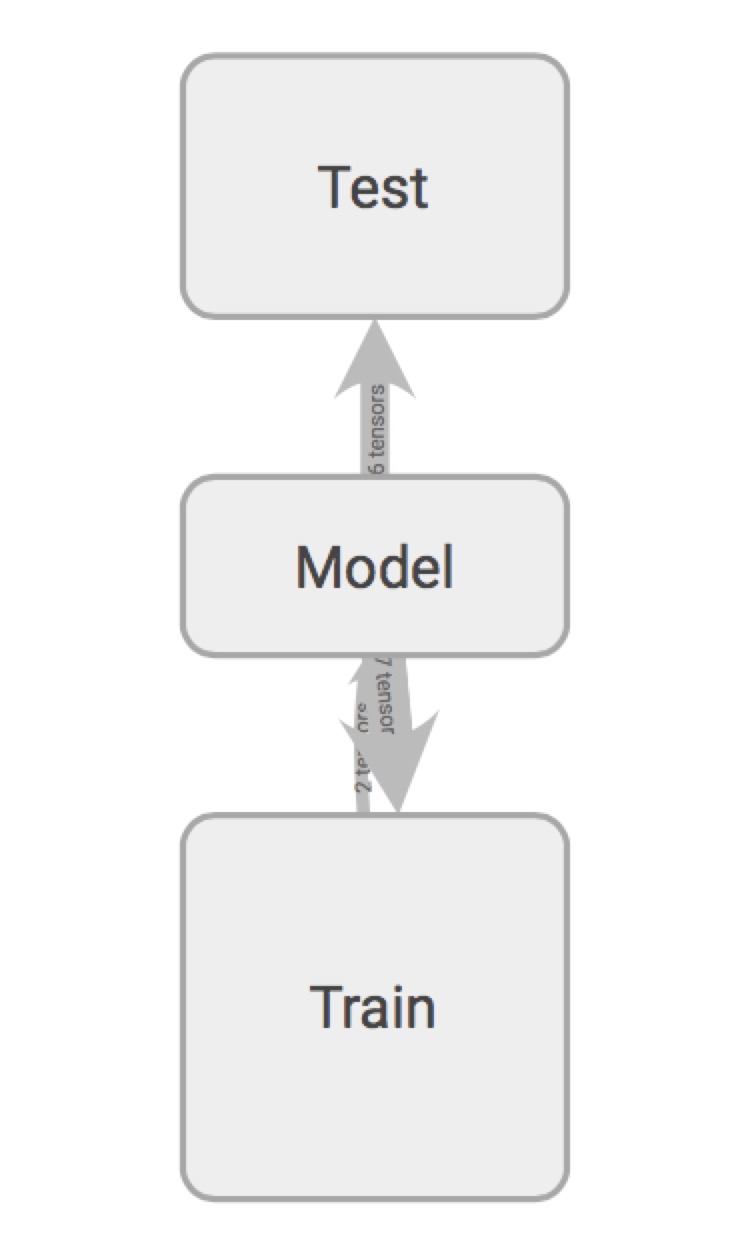
tensorboard 中的GRAPHS
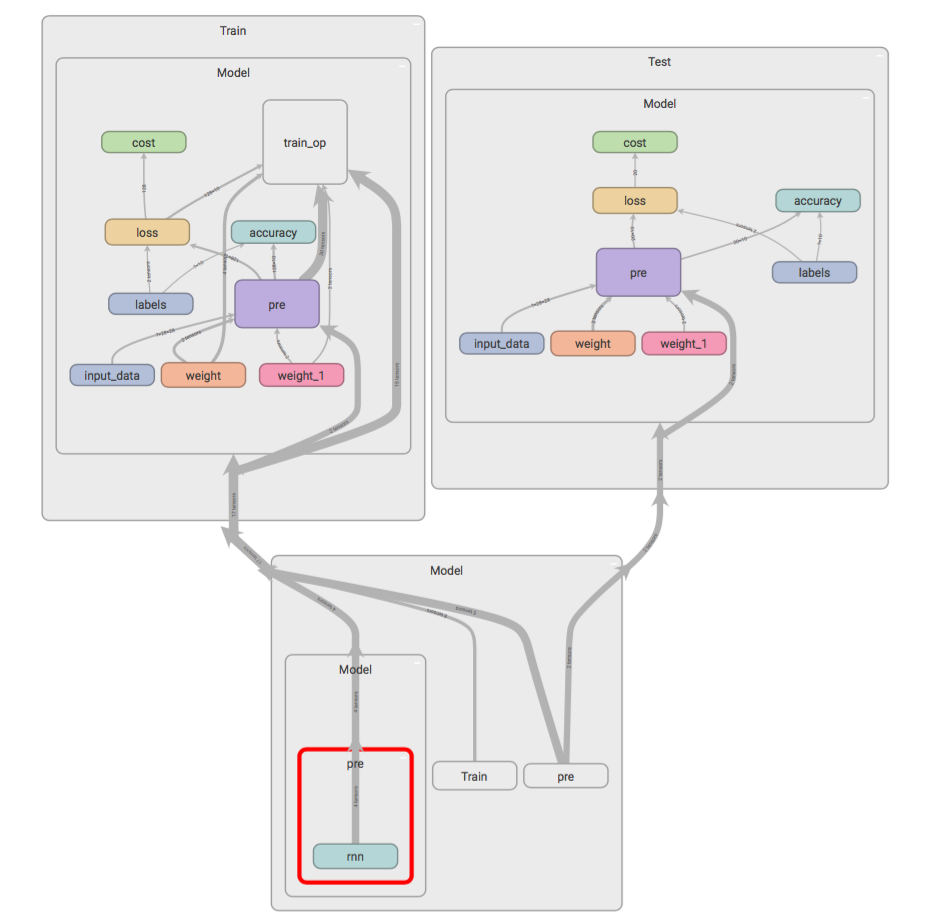
GRAPH展开
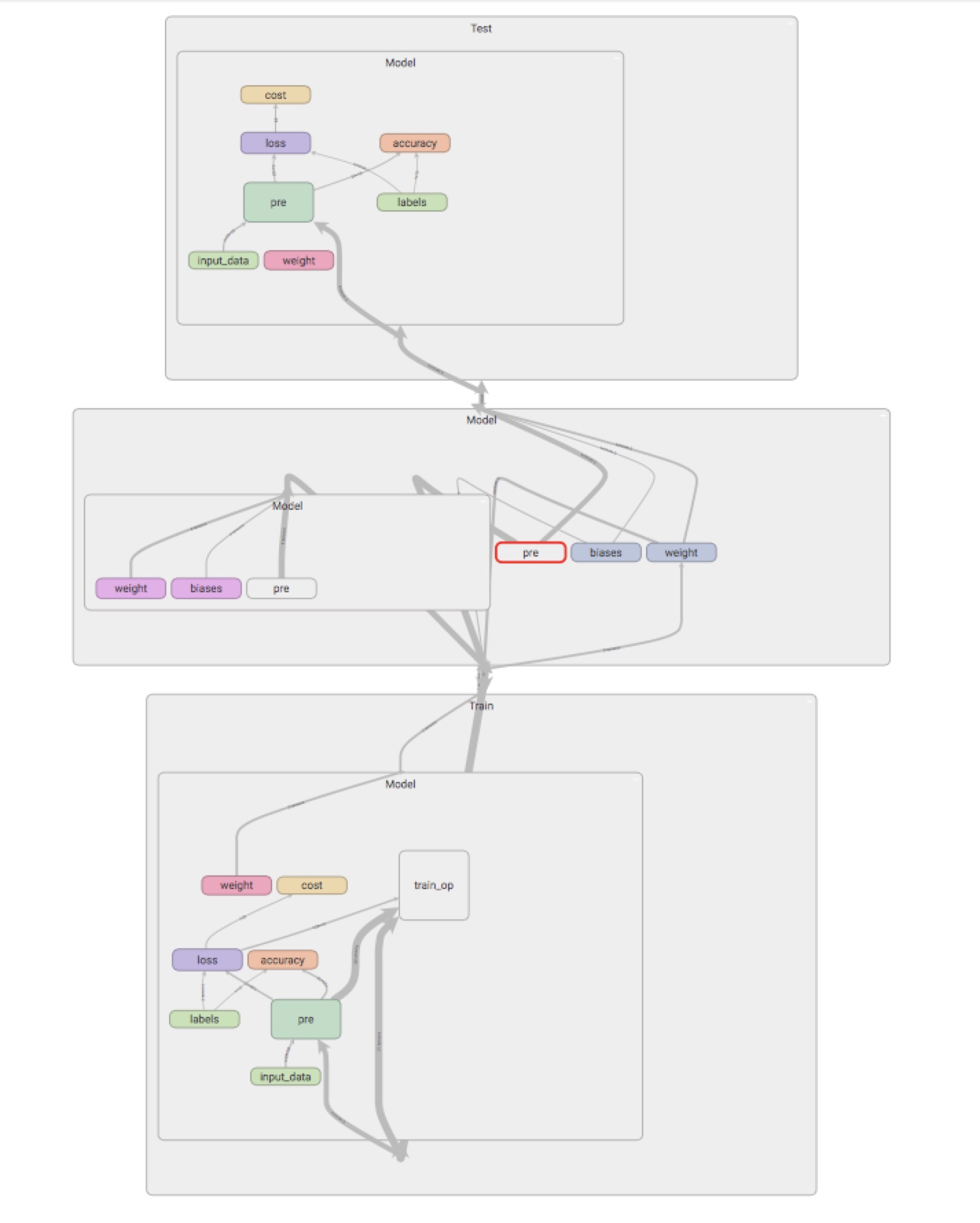
上面所展现的也是本文所做的主要工作,也是实现过程中踩过的坑,为了防止模型的过拟合,tensorflow提供了droupout机制,在训练过程中drop掉某些节点来防止过拟合,但是测试模型并不需要使用到dorp以及一些train_op,因此有的教程中会将is_training作为模型的一个变量。
首先将train_model和test_model分开定义,主要是为了便于使用tf.summary将训练模型和测试模型的accuracy和cost分别展现出来。
with tf.Graph().as_default(): initializer = tf.random_uniform_initializer(-train_conf.init_scale, train_conf.init_scale) with tf.name_scope("Train") as train_scope: with tf.variable_scope("Model", reuse=None, initializer=initializer): train_model = model(train_scope, train_conf, is_training=True) with tf.name_scope("Test") as test_scope: with tf.variable_scope("Model", reuse=True, initializer=initializer): test_model = model(test_scope, valid_conf, is_training=False) with tf.Session() as session: train_summary_writer = tf.summary.FileWriter('./model/tensorflowlogs/train', session.graph) test_summary_writer = tf.summary.FileWriter('./model/tensorflowlogs/test') session.run(tf.global_variables_initializer())
在使用tf.summary的时候的坑主要是在使用tf.summary.merge_all()的时候,具体的错误和解决方法参见参考文献第二个。
第二个坑主要是训练模型的accuracy在不断提高,loss在不断减少,但是测试模型的数据却非常混乱。
训练和测试模型的accuracy 和cost,Tensorboard中的GRAPHS如下
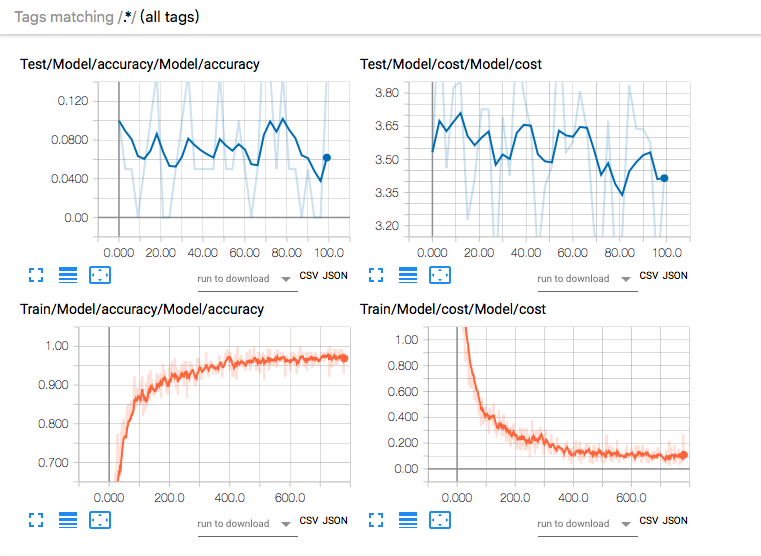
原先我开始怀疑是否是超参的设置问题,但是不管怎么调节其结果都没有什么变化,测试集的精度依旧很低,cost也没有变化。后面还调了网络结构,把该省的都省掉了,构造一个最简单的RNN网络,问题还是没有解决。很纠结。
后来开始怀疑是共享变量的问题,将所有的变量都加上tf.variable_scope(),问题依然存在,没办法在一个技术群里把这个问题提了出来,估计大部分人都没想过这个问题,没人回答。我很尴尬,最后实在没办法去youtube上找教程,想从一些教程里面找到是否有人会像我这样把train和test分开,找到一个类似的,只不过是使用的cnn解决mnist问题。
在他的技术讨论群里我把这个问题提出来后一个伙伴提醒我可能是tf.Variable()的原因,他在官网上把tf.Variable和tf.get_variable的区别发给我看了下,然后我把我的程序里面涉及到的tf.Variable改写成tf.get_variable,果然问题解决了,下面是改写前后的代码。
改写前
with tf.variable_scope("weight") as scope: self.weights = { # (28, 128) 'in': tf.Variable(tf.random_normal([self.n_inputs, self.n_hidden_units]), name=scope.name + 'in'), # (128, 10) 'out': tf.Variable(tf.random_normal([self.n_hidden_units, self.n_classes]), name=scope.name + 'out') } with tf.variable_scope("weight") as scope: self.biases = { 'in': tf.Variable(tf.constant(0.1, shape=[self.n_hidden_units, ]), name=scope.name + 'in'), # (10, ) 'out': tf.Variable(tf.constant(0.1, shape=[self.n_classes, ]), name=scope.name + 'out') }
改写后
with tf.variable_scope("weight") as scope: self.weights = { # (28, 128) 'in': tf.get_variable('in', initializer=tf.random_normal([self.n_inputs, self.n_hidden_units])), # (128, 10) 'out': tf.get_variable('out', initializer=tf.random_normal([self.n_hidden_units, self.n_classes])) } with tf.variable_scope("biases"): self.biases = { # (128, ) 'in': tf.get_variable('in', initializer=tf.constant(0.1, shape=[self.n_hidden_units, ])), # (10, ) 'out': tf.get_variable('out', initializer=tf.constant(0.1, shape=[self.n_classes, ])) }
改写前后的GRAPHS发生了改变,model中多了这两个变量,说明之前虽然model共享了,但是里面的变量依然没有共享。
总结
之前在看变量共享的文档时只是说tf.get_variable()对变量的复用和作用域会有影响,主要是很多源代码都是使用tf.Variable来定义变量的。官网上也明确说明最好使用tf.get_variable来定义变量。
但其实这里面的精髓还没有领会,model这个类共享了,而里面的参数竟然没有共享,有点想不通,或者说我的代码依然不严谨。
文献3中有提到变量的作用域机制,讲到通过tf.get_variable()所给的名字创建或是返回一个变量, 通过tf.variable_scope()为变量名指定命名空间。
参考文献
文中涉及到的完全代码
tensorflow.python.framework.errors_impl.InvalidArgumentError
Tensorflow 变量的共享