写在前面
随着业务场景的慢慢深入, 数据量的逐步增大, 模型的训练时间不断的变长, 导致模型训练成本逐步增大. 所以需要更加高效的提高硬件计算资源的利用率, 本文主要介绍安装GPU版本的XGBoost.
单机部署
安装前提是需要GPU驱动, cudnn等安装正确, 如果这步没有安装, 请参见Ubuntu16.04下安装安装CUDA9.0、cuDNN7.0和tensotflow-gpu 1.8.0以上的版本流程和问题总结的具体安装方式.
1、下载源码
在git clone下来的xgboost中执行
git submodule init git submodule update
更新子依赖, 或者使用:
git clone --recursive https://github.com/dmlc/xgboost
PS 如果从github上download xgboost源码压缩包, 后面的安装过程会出错, 原因是download过程不能将xgboost的子依赖项目下载下来. 20190823Update
2、新建build文件目录
在/xgboost, 目录下新建/build文件夹
cd xgboost mkdir build
3、编译源码
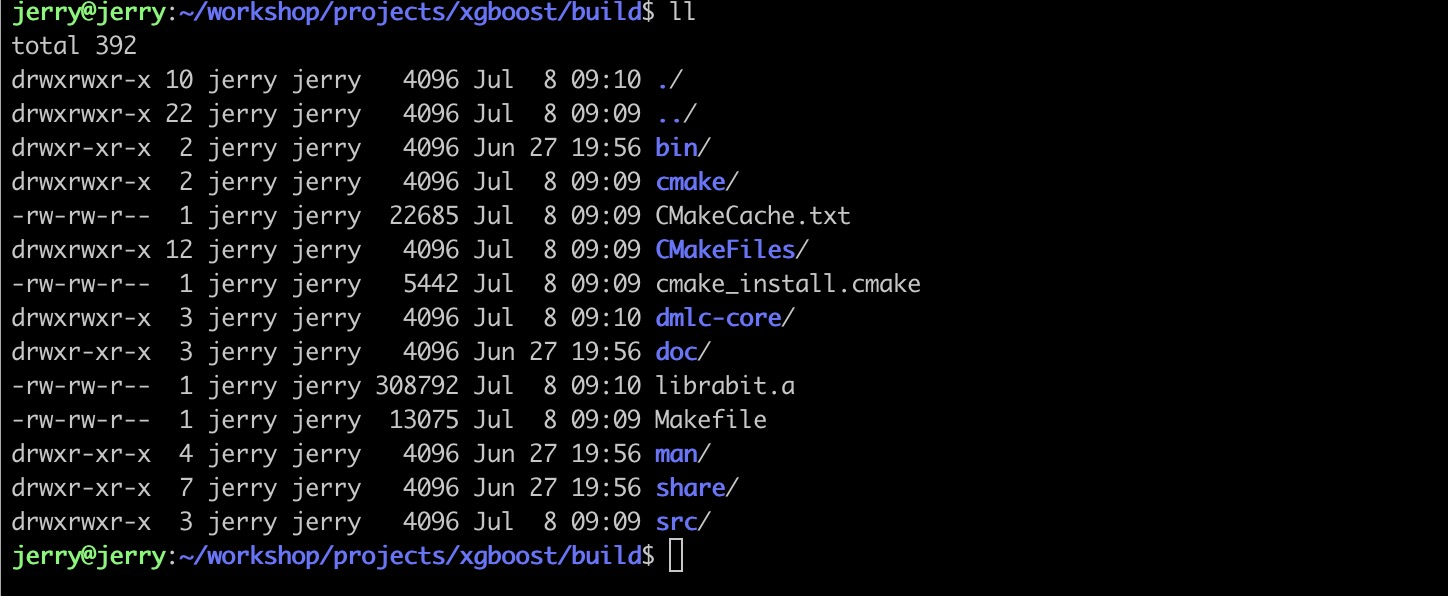
执行cmake
cmake .. -DUSE_CUDA=ON
执行结果如下图所示:
4、make
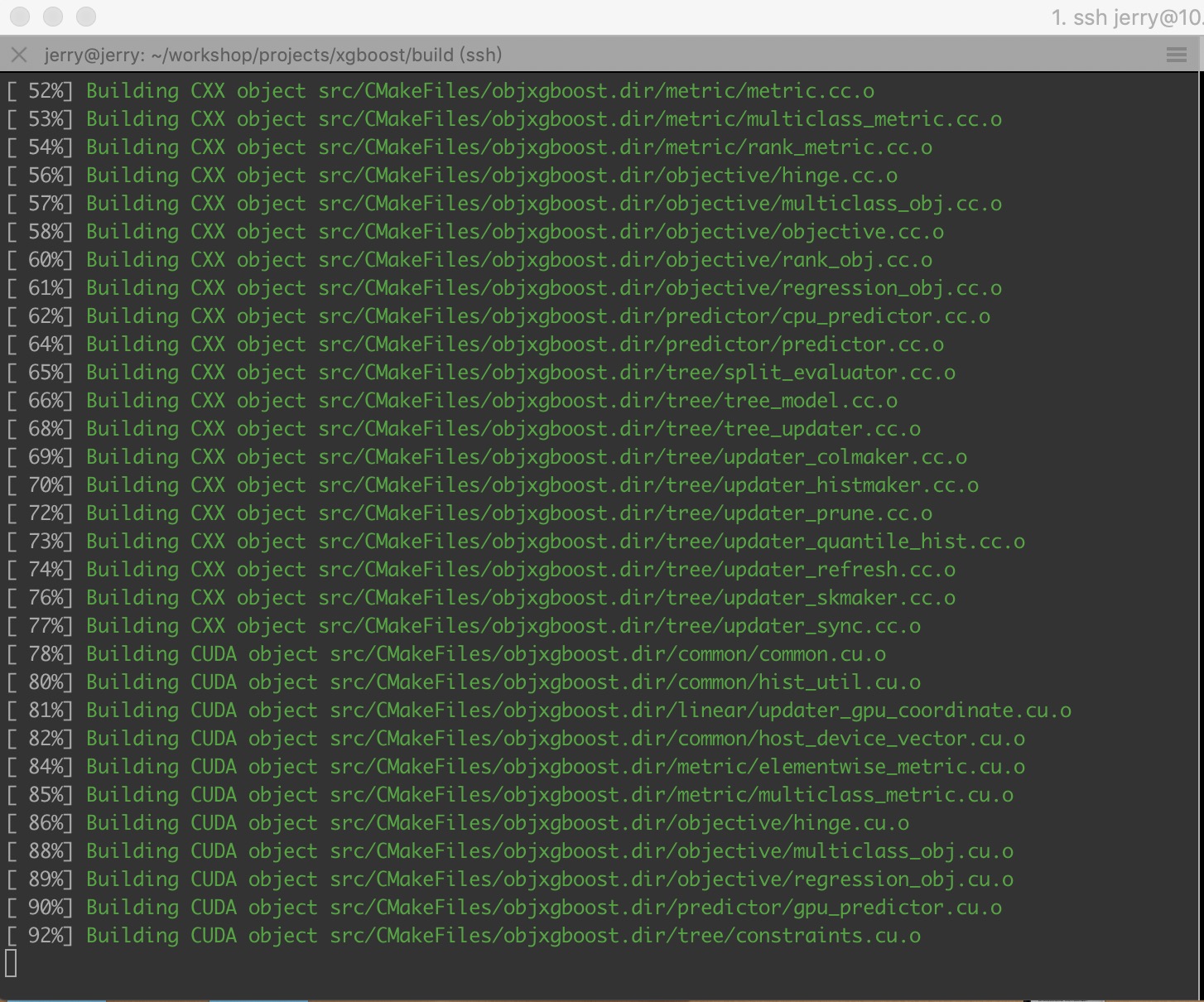
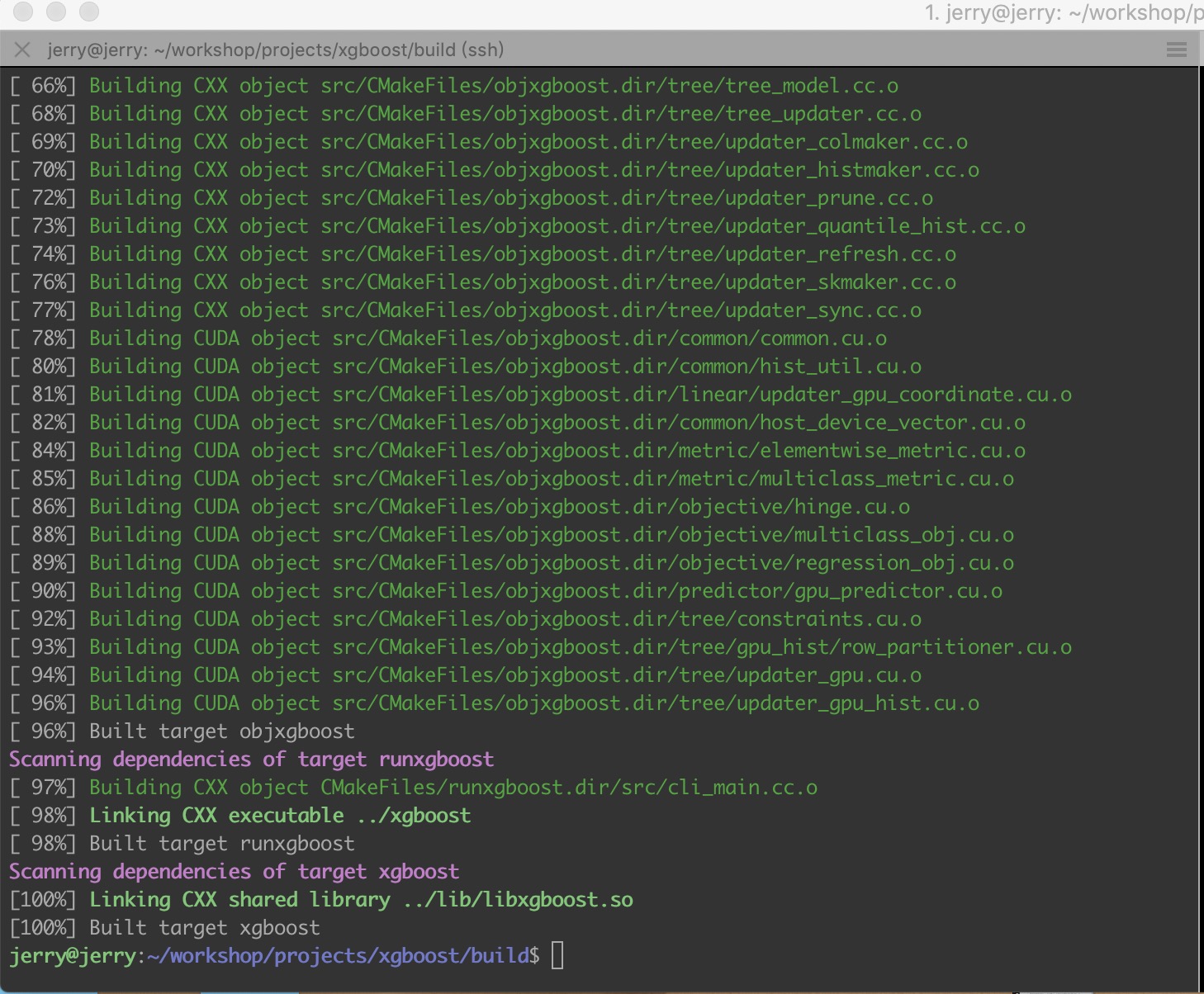
执行make
make -j4
执行过程和执行结果如下图:
PS很多教程中提到, 在make的过程中不需要用到-j4中的4, 他的解释是使用后会自动生成build目录, 但是我的理解是在新建的build目录下执行上面的命令, 所以不太理解他的做法, 另外我在pull源码下来后, 源码里事先没有build文件目录, 需要手动新建.
virtualenv中更新XGBoost
一般的, 为了不污染原始环境, 我们都会使用虚拟环境隔离开发环境, 比如virtualenv或conda. 我使用的是vitrualenv, 所以介绍virtualenv中如何更新, 其实方式比较简单.
直接pip uninstall XGBoost先卸载掉原始的XGBoost 然后重新安装即可. 虚拟环境下可以完美调用GPU运行XGBoost.
调用情况如下:
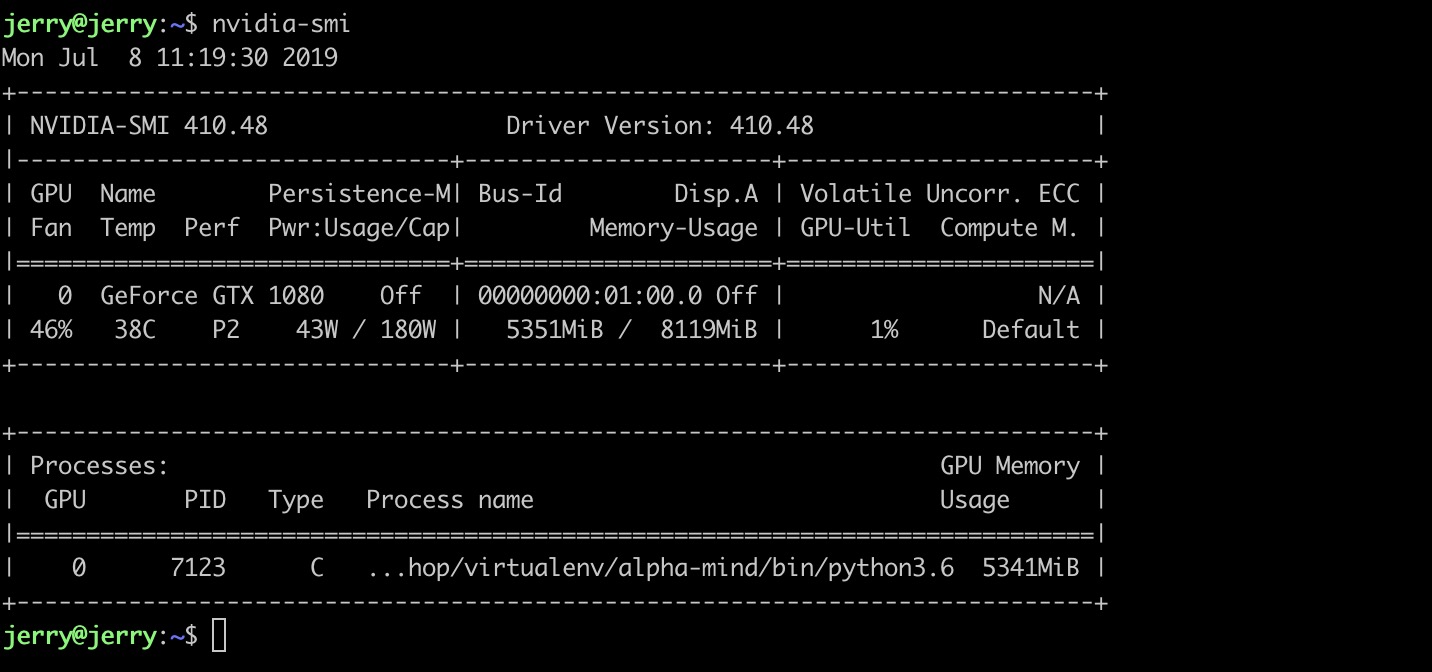
annaconda下面没有测试过, 可能也需要重新安装.
XGBoost的多GPU部署
[UPDATE20190710]
上面的初始化过程中, 是不能使用分布式GPU进行计算的, 而且只能使用单个的GPU, 为了能够使用分布式GPU训练, 需要设置USE_NCCL=ON, 另外, 分布式GPU训练依赖Nvidia的NCCL2, 需要另外安装. 特别的, 目前NCCL2只支持linux系统, 所以分布式GPU训练只支持linux系统.
详细的安装方式:
mkdir build cd build cmake .. -DUSE_CUDA=ON -DUSE_NCCL=ON -DNCCL_ROOT=/path/to/nccl2 make -j4
我在配置安装过程时, 使用的命令:
-DNCCL_ROOT=/usr/include
PS, 这里的分布式GPU训练, 笔者认为是单服务器多GPU训练, 并不是我们所谓的分布式服务器的方式, 不过暂时还没有验证.
NCCL2安装
NCCL是Nvidia Collective multi-GPU Communication Library的简称,它是一个实现多GPU的collective communication通信库,Nvidia做了很多优化,以在PCIe、Nvlink、InfiniBand上实现较高的通信速度。
-
1、登陆NCCL官网, 进行NCCL下载或者复制下载链接, 需要进行注册, 之前注册过的直接登陆即可.
-
2、点击下载, 进入NCCL下载页面.
-
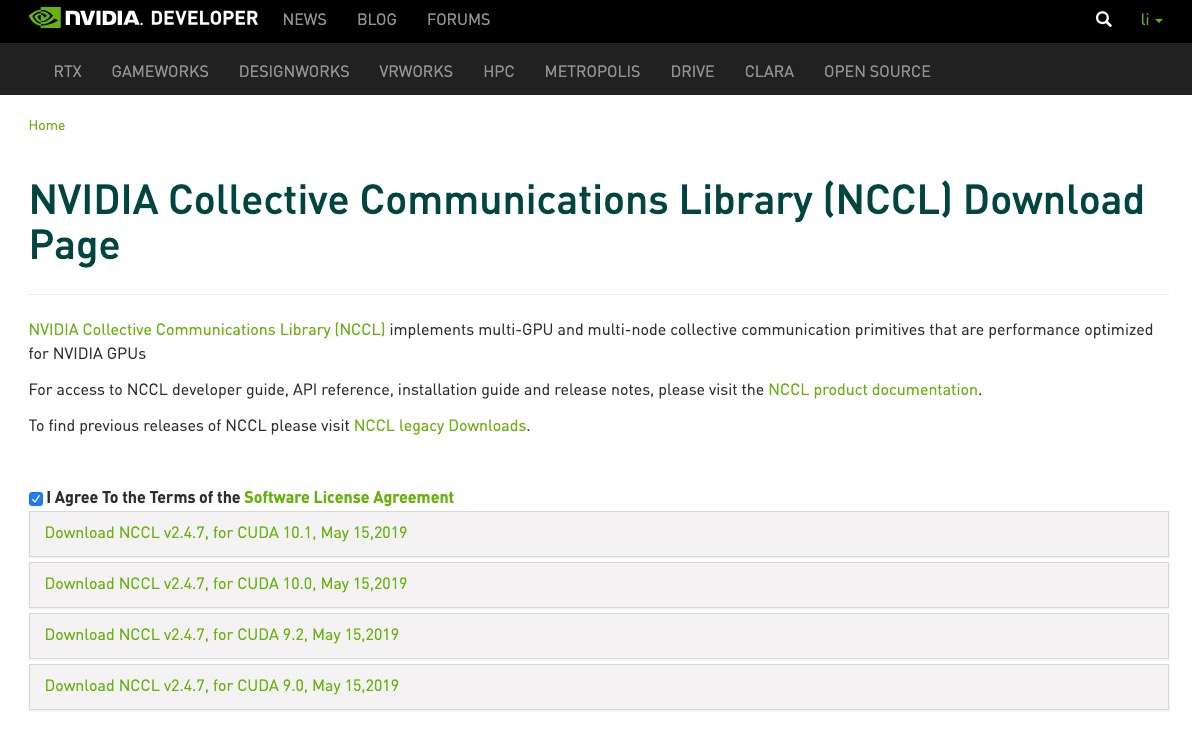
3、根据原先安装的cuda和cudnn版本以及操作系统版本, 选择对应的NCCL版本. 我们这里是根据ubuntu16.04和cuda10.0, 选择下载的版本是nvidia-machine-learning-repo-ubuntu1604_1.0.0-1_amd64.deb
-
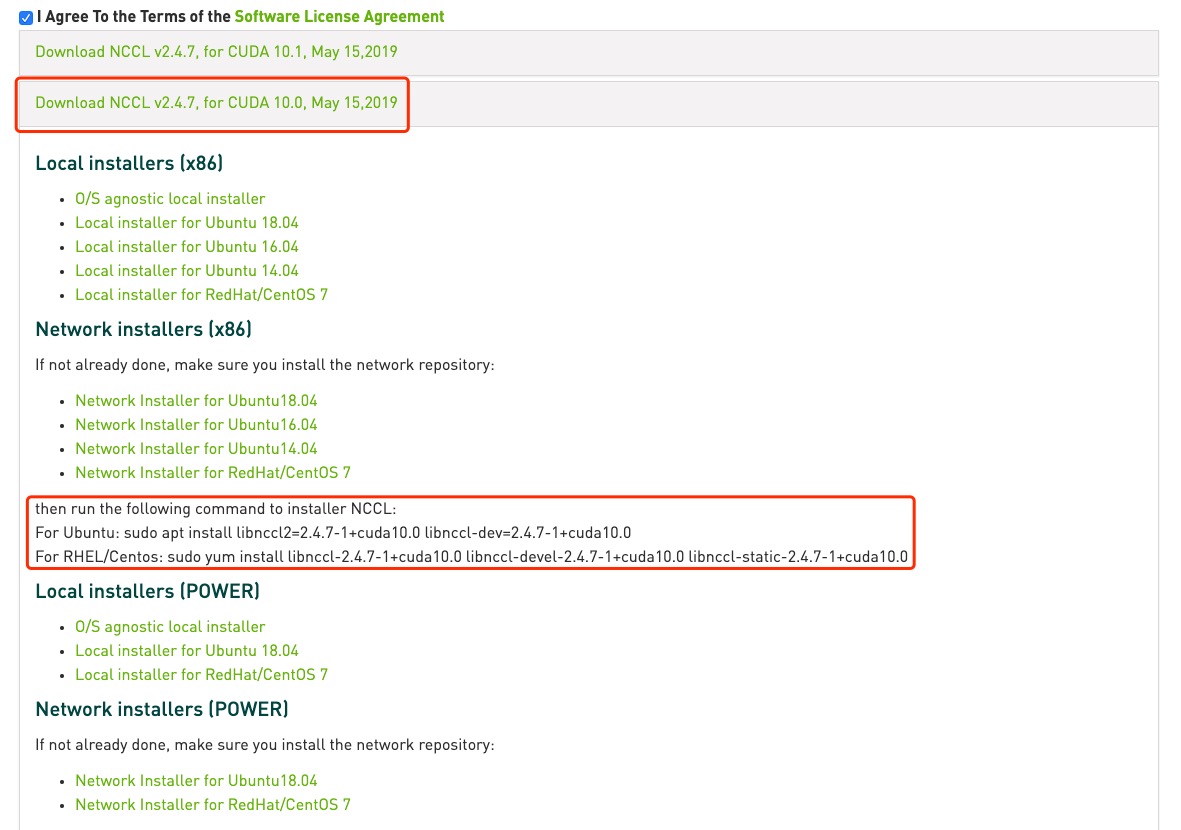
4、切换到NCCL下载的文件目录, 使用下面的命令进行安装
dpkg -i nccl-repo-ubuntu1604-2.4.8-ga-cuda10.0_1-1_amd64.deb
[2019-10-21 UPDATE]初次安装可能会出现下面的提示:
root@Super-Server:/home/soft# dpkg -i nccl-repo-ubuntu1804-2.4.8-ga-cuda10.1_1-1_amd64.deb Selecting previously unselected package nccl-repo-ubuntu1804-2.4.8-ga-cuda10.1. (Reading database ... 185150 files and directories currently installed.) Preparing to unpack nccl-repo-ubuntu1804-2.4.8-ga-cuda10.1_1-1_amd64.deb ... Unpacking nccl-repo-ubuntu1804-2.4.8-ga-cuda10.1 (1-1) ... Setting up nccl-repo-ubuntu1804-2.4.8-ga-cuda10.1 (1-1) ... The public CUDA GPG key does not appear to be installed. To install the key, run this command: sudo apt-key add /var/nccl-repo-2.4.8-ga-cuda10.1/7fa2af80.pub
按照提示, 执行
sudo apt-key add /var/nccl-repo-2.4.8-ga-cuda10.1/7fa2af80.pub
即可, 执行完成之后,会输出OK
- 5、更新APT数据库:
sudo apt update, 这一步需要操作, 不然第六步会安装不成功, - 6、利用APT安装libnccl2。
此外,如果您需要使用NCCL编译应用程序,则同时安装 libnccl-dev包。
如果您正在使用网络存储库,则使用以下命令。这种不推荐.
sudo apt install libnccl2 libnccl-dev
如果您希望保留较旧版本的CUDA,请指定特定版本,例如上图第二个框框中的内容:
sudo apt install libnccl2=2.4.7-1+cuda10.0 libnccl-dev=2.4.7-1+cuda10.0
请参阅官网安装手册以了解确切的软件包版本。
- 7、链接到正常位置
完成解压安装,将NCCL的include 和lib 文件夹下文件放到对应 /usr/local/include /usr/local/lib 目录下。
sudo mkdir -p /usr/local/cuda/nccl/lib sudo ln -s /usr/lib/x86_64-linux-gnu/libnccl.so.2 /usr/local/cuda/nccl/lib/ sudo ln -s /usr/lib/x86_64-linux-gnu/libcudnn.so.7 /usr/local/cuda/lib64/
执行下面的命令:
cat /usr/include/cudnn.h | grep CUDNN_MAJOR -A 2
执行效果如下:
ubuntu@AiDLHost:~$ cat /usr/include/cudnn.h | grep CUDNN_MAJOR -A 2 #define CUDNN_MAJOR 7 #define CUDNN_MINOR 5 #define CUDNN_PATCHLEVEL 1 -- #define CUDNN_VERSION (CUDNN_MAJOR * 1000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL) #include "driver_types.h"
多卡运行测试
nccl的安装教程不多, 也没有提供什么测试案例, 所以只能直接运行xgboost,观察多张卡的使用情况, 我使用xgboost源码下的demo进行测试:
测试demo:
~/xgboost/demo/gpu_acceleration
运行之前查看GPU的状态:

运行过程中查看GPU的运行状态:

从上图中可以看出demo运行过程中4张卡都被占用. 所以应该是安装成功了(ps没有在未安装nccl2之前尝试运行demo, 所以不确定是不是nccl2起作用了).
另外, demo的运行结果:
[2996] test-merror:0.031765 [2997] test-merror:0.031758 [2998] test-merror:0.031751 [2999] test-merror:0.031772 GPU Training Time: 241.86946082115173 seconds [2995] test-merror:0.031648 [2996] test-merror:0.031641 [2997] test-merror:0.031655 [2998] test-merror:0.031634 [2999] test-merror:0.031641 CPU Training Time: 3853.92036151886 seconds
从运行结果可以看出, 相同的迭代次数下, GPU的运行时间大大缩短.
注意点
1、cmake 版本更新
方法一
在编译过程中,可能会出现下面的问题, 原因是cmake的版本太低, 需要更新cmake版本.
CMake Error at CMakeLists.txt:62 (cmake_minimum_required): CMake 3.12 or higher is required. You are running version 3.5.1
版本更新教程见StackExcahnge
简单的安装步骤:
step 0: sudo apt remove cmake step 1: cd /opt step 2: wget https://github.com/Kitware/CMake/releases/download/v3.15.0-rc3/cmake-3.15.0-rc3-Linux-x86_64.sh step 3: chmod +x cmake-3.*your_version*.sh step 4: sudo bash cmake-3.*your_version*.sh step 5: sudo ln -s /opt/cmake-3.*your_version*/bin/* /usr/local/bin
方法二
官网下载链接
下载完成之后, 解压, 安装
tar -zxvf cmake-3.15.1.tar.gz ./bootstrap make make install
2、安装XGBoost gpu版本, python的版本必须大于3.5
报错如下:
RuntimeError: Python version >= 3.5 required.
XGBoost_GPU使用
[UPDATA20190710]
在使用gpu训练XGBoost模型的时候, 如果training params中的max_depth设置过高, 可能会引起服务器内存过高的问题.